AlexNet分类图片全纪录
###背景
- 因为工作需要,之前用谷歌网络InceptionV3虽然分类图片成功,并且效果也很好,但是因为谷歌网络是并行网络,说是22层网络,实际上有152层,在项目中表现为:准确率很高,但是CPU处理预测一幅图片需要0.7s,耗时较多。
- 考虑到AlexNet是只有8层的轻量级网络,也比较经典,尝试使用分类。事实上,使用AlexNet做迁移学习目前是非常少的,之前深度学习开始火的时候,倒是比较多,因为当时受限于算力,所以还是有很多人做了,但是也都是基于Caffe
- 这次,在算力已经大力发展的现在,用AlexNet做迁移学习意义不大。因此,直接用AlexNet做分类任务
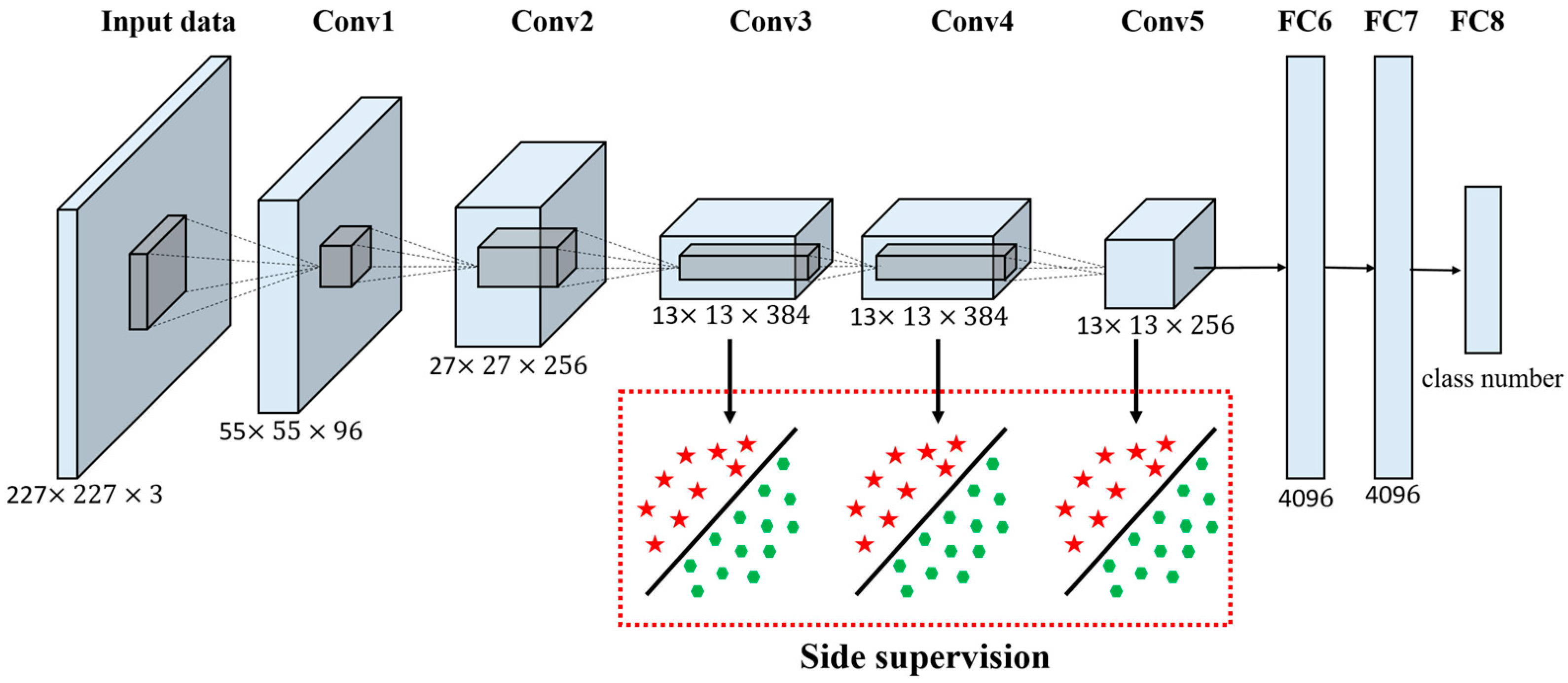
解读AlexNet
AlexNet的解读已经非常多,贴个原文链接吧,然后贴个中英文对照版的博客.下面是一些公认的AlexNet所做的贡献:
- alexnet中使用relu作为cnn的激活函数,验证效果远远好于sigmoid,解决了网络较深时的梯度弥散问题,并且加快了训练速度,虽然很早relu激活函数就存在了,但是alexnet成功的把它发扬光大。
- 训练时使用dropout来避免模型过拟合,dropout同样是已存在的技术,但是在alexnet验证了它的有效性,虽然之后有了BN之后一般不再使用dropout了
- 使用最大池化,避免了平均池化的模糊效果(突出重点特征)
- 提出了LRN层,对局部神经元的活动创建竞争机制,使得其中响应较大的值变得相对更大,并抑制其他较小的神经元,增强了模型的泛化能力
- 基于GPU使用CUDA加速神经网络的训练
#用TensorFlow实现AlexNet网络
首先,感谢这位前辈的博客,基本代码都是来自于他,然后做了稍许改变。里面的注释也都很详细,可以根据自己的需求来修改。
重点内容-调参
我是做二分类任务,一类NG图片和二类OK图片各750张左右。即使AlexNet自身已经做了dropout防止过拟合,实际上和使用Inception做迁移学习比,AlexNet仍然存在着过拟合的问题。从头开始做二分类任务表现:为训练集上,batchSize设置8的时候,训练最后在训练集的准确率基本都是100%(8个里面对8个),但是在测试集上,只有90%的正确率。为此,我做了以下尝试来提高准确率:
- 增加训练次数,调整batchSize大小,最后表现如下:
- 增加其他种类的图片,提高模型的泛化能力,增加两类图片,guitar,motorbike各五百张,这样训练次数增加到8000次,批次大小8,测试结果出乎意料地提高很多,达到97.9%:
- 增加OK和NG的训练样本个数,到各1200张图片,训练次数到40000,批次大小设置为2,最后预测结果准确率95.8%
- 再次增加图片种类,这次添加flowers,animal和airplane类别,共训练7类,即使是用AlexNet迁移学习,也只不过是先在cifar-10数据集上先分类了10类而已,基本差别不大,通过多次调整批次大小,增减训练周期,得到模型。但是最终结果,准确率也只有97.9%不再增加。
结论
- 改变批次和增多训练次数可提高准确率,前者一般靠运气
- 网络从头开始训练而非迁移学习的话,一般会存在过拟合,这是因为网络结构参数多于预测分类所需要的参数,这时可以通过增加样本类别提高泛化能力
- AlexNet用于图片分类还是有很大的局限性,本身全连接层较多,容易出现过拟合。另外网络只有8层,不够深,一般层数越多效果越好,所以分类能力有限

