以AlexNet分析,对比pytorch和TensorFlow
背景
- 先前的深度学习都是使用的TensorFlow框架的,这是因为TensorFlow占领市场较早,生态社区建立得早,但是不得不说,tf仍然是公认的难用。
- 使用pytorch,在pytorch官网上稍微花点时间,就可以部署好。比原本从python到C++部署TensorFlow的时间缩短好几倍。
- 另外pytorch也是公认的易于上手,相比TensorFlow这种反人类的设计,可以说非常人性化了
- 这篇博客就是以AlexNet为例,一步步分析网络。再对比TensorFlow和pytorch的不同,也算是是为了学习。
分析网络
先上个网络结构图,这个图片上一篇博文里面已经放过了,基本表示了8层网络的结构
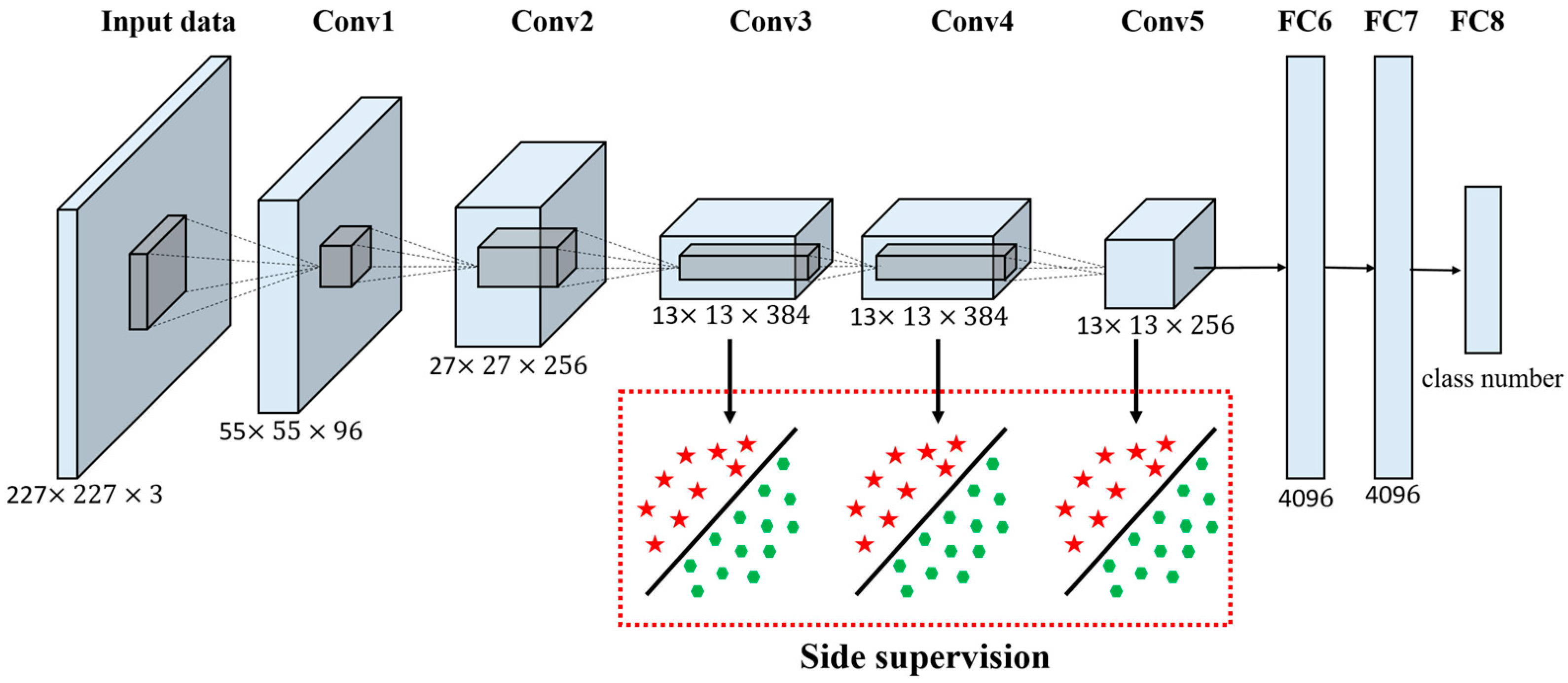
输入图片是227\*227的RGB三通道图片,先后经过五个卷积层,和三个全连接层,得到输出。这里面五个卷积层:

卷积层的作用就是提取信息,减维度。第二个卷积层为例,参数有:
Conv_input卷积输入,
Kernal_size卷积核大小,
Kernal_nums卷积核数目,
Stride步长
Pad补丁
Conv_output卷积输出
假设输入是等高宽的,则输出就表示成:
输出宽(高)=(输入的宽(高)-卷积核宽(高)+2*补丁)/ 步长+1
输出通道数 = 卷积核数目池化层,暴力降维。以第一个池化层为例,参数有
Pool_input池化输入
Kernal_size卷积核大小
Stride步长
Pool_output卷积输出
同样假设输入等宽高,输出计算:
池化输出 = 宽(高)=(输入的宽(高)-卷积核宽(高))/ 步长+1全连接层
全连接层没啥好说的,就是映射。下面就是AlexNet公认的几个贡献:
- ReLU作为激活函数
- Dropout避免模型过拟合
- 最大池化
- 提出LRN层
- GPU加速
TensorFlow下的AlexNet
代码使用来源:修炼之路
1 | #第一层卷积层 |
pytorch下的AlexNet
代码来源:sjtu_leexx
1 | class BuildAlexNet(nn.Module): |
直观比较
- 直观感受就是pytorch比TensorFlow好多了。
- 同时pytorch是有预训练数据的,可以用来迁移学习。
- Tensorflow供给用户修改的参数实在太多了,细致到每一层的命名。而pytorch封装得很好,参数就少很多。最后结果就是使用起来,其实更方便。
代码上比较
用TensorFlow写一个卷积层,第二层为例:
1 | #第二层卷积层 |
- 每层都命名,这可能对可视化调试有些帮助,但是在网络逐渐变深的现在意义不大。
- 偏置和卷积核都用tf.Variable设置的变量,而且变量还是多,繁琐
同样用pytorch写第二个层,就可以是
1 | nn.Conv2d(64, 192, 5, 1, 2), |
这写在nn.Sequential函数里面,会按序传播的。补一句解释:inplace为True,将会改变输入的数据 ,否则不会改变原输入,只会产生新的输出。是用于反向传播的。
最后说一句,pytorch做迁移学习是真方便

